Current and upcoming use cases of strong AI systems, for the most part, won’t be quick one-off sessions. Software engineers using code assistants might iterate on a tricky new feature in a large codebase over a lengthy AI-assisted edit conversation. Business professionals might chat with the same internal document for many queries in a row, performing extensive summarization, search, and data analysis. General users might employ computer use agents for long chains of everyday tasks, even giving input context that encodes some of their personal details.
To make these use cases more failproof, we at least need to better understand model safety in the multi-turn setting. However, the bulk of adversarial robustness and redteaming research for LLMs has focused on the single-turn regime, leaving multi-turn attacks (and defenses) comparatively underexplored.
What the research literature does agree on is that frontier language models are persistently and acutely vulnerable to multi-turn attacks. While single-turn jailbreaks often involve complex adversarial design—ranging from discrete optimization of an adversarial suffix [1] to character-level ciphers and encodings [2] [3]—multi-turn jailbreaks can be crafted with straightforward, human-interpretable heuristics. In the ``Crescendo’’ attack from Russinovich et al. [4], a human attacker makes several simple queries in conversation with a model, beginning with benign queries and gradually escalating to unsafe queries relevant to the target intent. More recently, Scale AI [5] enlisted expert human red-teamers for successful multi-turn conversation jailbreaks against several highly robust models, defended with methods such as latent adversarial training [6] [7] and circuit-breakers [8].
These previous works have focused on multi-turn attacks in a manual setting, which can be costly in terms of expert-level man-hours and are not easily scalable. Additionally, manual prompt optimization typically covers a human-legible subset of the input search space, and can fail to discover more idiosyncratic adversarial inputs which may be equally as, or more effective than, manually discovered attacks. To gain a more comprehensive, systemized understanding of model vulnerabilities in the multi-turn setting, we supplement previous manual red-teaming with a potent automated attack that we call Cascade. As an overview, Cascade employs attacker LLMs in the place of human red-teamers and uses well-tuned tree search and prompt optimization heuristics, reaching jailbreaking efficacies comparable with that of expert manual red-teaming.
Attacking models with Cascade
Cascade searches for a multi-turn conversation trajectory with a victim model where initially benign queries escalate into unsafe queries with jailbroken model responses. The resulting conversation trajectory resembles the jailbroken multi-turn conversations in Crescendo [4], which a human red-teamer performs iteratively. Instead of Crescendo’s single-path iteration, Cascade performs a tree search over several parallel conversation branches. The broad implementation details of this tree search are standard: we alternate between a generation step, where an attacker LLM generates next conversation steps at select nodes in the current tree, and a pruning step, where only the top-k current nodes, according to some scoring system, are kept in the tree. (Note that the pruning step is equivalent to beam search.) For competitive advantage reasons, we do not discuss further details of the search algorithm.
We draw an analogy to previous jailbreaking works such as PAIR [2] and TAP [3] in which tree search with an attacker LLM is used for automated prompt optimization. In PAIR [2], an attacker LLM writes an input to the target LLM and self-reflects on the resulting response in a loop, iteratively refining a jailbreak prompt across multiple attempts. TAP [3] transplants this reflect-and-refine strategy into a tree search, where each node corresponds to a different multi-query prompt optimization history (i.e. the attempted jailbreaks, target model responses, and self-reflections, for each past attempt). As reported in the original work, the tree search and pruning strategy of TAP greatly improves jailbreak efficacy compared to the iterative PAIR strategy [2]. Similarly, by adapting the iterative “escalation” strategy of Crescendo to a tree search in Cascade, we’re able to develop a highly potent multi-turn jailbreaking system beyond Crescendo.
The beam search component of Cascade is crucial for finding highly effective jailbreaks. The heuristic value in our beam search is derived from robust, well-tuned automated judging pipelines we’ve developed in-house at Haize Labs. These pipelines provide high-quality evaluations and scores for conversation branches, guiding Cascade towards optimal jailbreaking conversation trajectories accurately and quickly. Again, for competitive advantage reasons, we don’t share further details about our judging pipelines or about the optimization signal used in Cascade.
Cascade is competitive with expert human red-teaming
To validate our attack’s usefulness in the broader context of current redteaming techniques, we require comparisons of Cascade against two types of attacks: strong manual multi-turn attacks and state-of-the-art single turn attacks. Li et al. from Scale AI [5] provide both the baselines we need: they benchmark expert-level human redteamers against several single-turn attacks on several highly robust target models. They evaluate all attacks on a modification of the HarmBench test set with all copyright-related behaviors removed, and judge model responses for harmfulness using the HarmBench judging prompt with GPT-4o. Likewise, we run our Cascade experiments on the target models from LAT [6] and Circuit Breakers [8] and benchmark using the same modified HarmBench test set. (Note that, for our judging harness, we switch out GPT-4o-mini in place of GPT-4o for the sake of cost efficiency.)
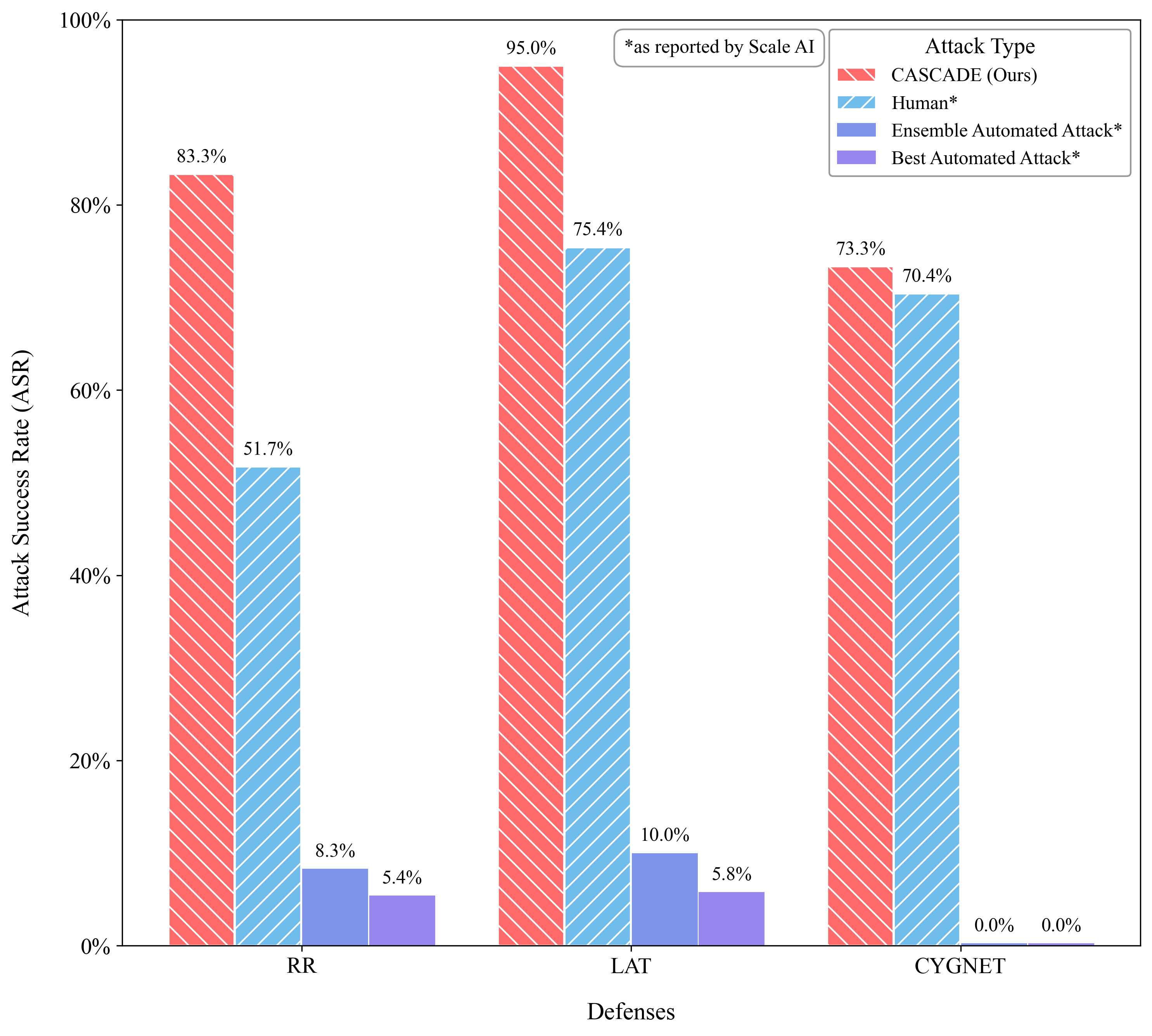
Our results are shown in Figure 1. Cascade is a state-of-the-art multi-turn attack on the benchmarked target models, obtaining significantly higher ASRs on the Gray Swan RR model and the Llama 3 LAT model compared to Scale AI’s human redteamer attacks, and lagging only one percentage point behind Scale AI human attacks on Gray Swan Cygnet.
Aside from the limited set of highly defended models in Figure 1, we benchmark Cascade on a handful of widely-used frontier models. Our results are shown in Table 1. For the evaluations in Table 1, we use a subset of 108 HarmBench intents, class-balanced across each of the 6 non-copyright risk categories (i.e. 18 intents per category). We call this subset HarmBench-108. On safety-trained models that lack defenses such as latent AT or circuit-breakers, we’re able to elicit harmful model responses on the vast majority of behaviors in HarmBench.
| Model | ASR |
|---|---|
| Claude 3.5 Sonnet | 88.89% |
| Llama 3.1 8B Instruct | 97.22% |
Table 1: Cascade obtains extremely high ASRs on both Claude-3.5-Sonnet and Llama-3.1-8B, both widely used advanced-capability models at the time of writing.
Implications
Not only does multi-turn model usage harbor particularly severe vulnerabilities for current LLMs, but manual red-teaming alone is insufficient for accurately evaluating models for safety. Cascade is a first attempt at building an automated multi-turn redteaming suite that already proves to be highly potent, moreso than manual multi-turn jailbreaks on the majority of models. We encourage the research community to devote increased attention to red-teaming and model safety through the development of, and mitigation against, multi-turn attacks which are automated.
If you have any questions or want to discuss this work, feel free to reach out to us at [email protected]!
References
- Universal and Transferable Adversarial Attacks on Aligned Language Models
- Jailbroken: How Does LLM Safety Training Fail?
- Endless Jailbreaks with Bijection Learning
- Great, Now Write an Article About That: The Crescendo Multi-Turn LLM Jailbreak Attack
- LLM Defenses Are Not Robust to Multi-Turn Human Jailbreaks Yet
- Defending Against Unforeseen Failure Modes with Latent Adversarial Training
- Latent Adversarial Training Improves Robustness to Persistent Harmful Behaviors in LLMs
- Improving Alignment and Robustness with Circuit Breakers