Lately, we’ve been working on understanding the impact of model capabilities on model safety.
Models are becoming more and more capable. Recently released models may be better aligned with human preferences through more sophisticated safety guardrails; however, when jailbroken, these models can incorporate deep world knowledge and complex reasoning into unsafe responses, leading to more severe misuse.
We believe that more powerful models come with new, emergent vulnerabilities not present in small models. We explore this intuition by devising an attack with a strikingly simple design philosophy: design an instruction-based attack with hyperparameters that modulate its complexity. We believe this design pattern is an effective way to make scale-agnostic attacks, which can be optimized towards models of varying capabilities with light hyperparameter tuning.
A common method of jailbreaking consists of using text encodings and obfuscations such as leetspeak, Base64, binary, ASCII, and Morse code. [1] We utilize more complex and previously unseen encodings by programatically creating new encoding languages on the fly. In our bijection learning scheme, we generate a mapping from each English alphabet letter to other characters/strings, and instruct the model to understand and write text in the encoding induced by this mapping — in a “bijection language”. We call this the bijection learning jailbreak.
The Bijection Learning Scheme

In bijection learning, we teach the model a custom, encoded language. This language is a random mapping of English characters to another set of tokens and is programatically generated. A simple example would be a Caesar cipher, which maps each alphabet letter to its respective letter some number of steps down the alphabet. However, our bijection learning mappings are much more creative than that. For example, we can choose to map alphabetical letters to other alphabetical letters in any permutation, to n-digit numbers, or even to random tokens from the model’s tokenizer. We call this mapping choice a bijection type.
There are many ways to control the difficulty of the language we teach to the model.
One way is the bijection type. We see that bijection type has a major impact on how learnable the bijection language is for the model. Simple alphabetical mappings may look quite similar to encodings like Caesar cipher and are easier to learn. On the other hand, tokenizer-based mappings may be very bizarre-looking and are more difficult to learn.
Another difficulty lever is the fixed size, or the number of letters in the alphabet that we map back to themselves — fixed points in the mapping. Fixed size is a more fine-grained difficulty hyperparameter and can range anywhere from 0 to 26 letters. Smaller fixed sizes require the model to encode almost every character, making for more difficult bijection languages, while larger fixed sizes are closer to plain text, making for easier bijection languages.
For smaller models, like gpt-4o-mini, we want to teach the model a simple language, one with a simple bijection type and a high number of fixed points. For stronger models, like Claude 3.5 Sonnet, we create much more complex languages using difficult bijection types (such as 5-digit numbers!) with very few fixed points. (We’ll see how this affects jailbreak efficacy later on, and explore a few deeper implications of this.)
After generating a new mapping, we teach a model the bijection language with an extensive multi-turn prompt:
- We directly specify the character mapping in the initial system prompt.
- We provide example English-to-bijection-language translations (of Paul Graham essay excerpts!).
- We provide a benign conversation history fully in bijection language.
Finally, we append any harmful intent in bijection language to the prompt, perform inference, and if successful, receive a response in bijection language. Inverting the bijection language mapping automatically recovers harmful content from the model’s response!
Bijection Learning Attacks Are…
Automated
Naturally, we want to formulate bijection learning as an automated attack. As with other adaptive attack schemes (Chao et al. [2], Mehrohta et al. [3], Andriushchenko et al. [4]), we perform an automated best-of-$n$ attack. For some small, fixed attack budget $n$, on each attempt, we randomly generate a mapping and attempt a bijection learning jailbreak; if successful, we’re done, and if unsuccessful, we retry with a new random-generated mapping, up to $n$ times. Other adaptive attacks like PAIR [2] and TAP [3] typically use attack budgets of 20-40 and we do the same.
We evaluate our attack on two benchmarks: a 50-behavior subset [2] of AdvBench (introduced in the GCG paper [5]), and the full test set of HarmBench [6], containing 320 behaviors. We attack the full GPT-4o and Claude 3 model families. For the best hyperparameter settings found for each model, we report the Attack Success Rate (ASR) on our benchmarks.
With modest attack budgets, we’re able to break our models on a wide range of harmful behaviors! Even on an extensively safety-trained model like Claude 3.5 Sonnet, and a challenging safety dataset like HarmBench, our automated bijection learning attack elicits unsafe responses on 86.3% of the behavior set.
AdvBench-50
| Model | Bijection type | Fixed points | Attack budget | ASR |
|---|---|---|---|---|
| Claude 3.5 Sonnet | digit | 10 | 9 | 94.0% |
| Claude 3 Haiku | letter | 10 | 21 | 92.0% |
| Claude 3 Opus | digit | 10 | 6 | 94.0% |
| GPT-4o-mini | letter | 18 | 47 | 88.0% |
| GPT-4o | letter | 18 | 39 | 66.0% |
HarmBench test set
| Model | Bijection type | Fixed points | Attack budget | ASR |
|---|---|---|---|---|
| Claude 3.5 Sonnet | digit | 10 | 20 | 86.3% |
| Claude 3 Haiku | letter | 14 | 20 | 82.1% |
| Claude 3 Opus | digit | 10 | 20 | 78.1% |
| GPT-4o-mini | letter | 18 | 36 | 64.1% |
| GPT-4o | letter | 18 | 40 | 59.1% |
Table 1: Our full evaluations on a wide range of frontier models with both AdvBench-50 and HarmBench.
Universal
Another property that powerful jailbreak methods might have is universality, or the ability to successfully break models on any harmful instruction without any instruction-specific modifications. Universal attacks are particularly effective because they require little expertise or overhead to use; often, you just paste in a prompt template, slot your harmful instruction into the template, and run the attack. Indeed, some popular attack methods, like Pliny the Prompter’s manual templates [7], are universal!
Besides the best-of-$n$ setting, our bijection learning scheme can also be used as a universal attack. Instead of randomly generating the mapping on each query, we search for one strong mapping and use it deterministically on a wide range of harmful instructions. From our results in Table 1, we view the saved inputs and responses for each model, and pick out universal attack candidates from any mappings which garnered particularly unsafe responses for particularly malicious behaviors. We benchmark our best universal attacks for each model and compare them to the Pliny attack from [7] for the same models. We attempted other universal attack methods too [5], but found that they struggled to transfer to frontier models. We thus omit them from our study:
Universal attacks on HarmBench
| Model | Bijection Universal | Pliny Universal |
|---|---|---|
| Claude 3.5 Sonnet | 50.9% | 50.0% |
| Claude 3 Haiku | 39.1% | 15.9% |
| Claude 3 Opus | 41.8% | 65.9% |
| GPT-4o-mini | 26.3% | 25.0% |
Table 2: ASRs for bijection learning prompts with the strongest manually discovered mapping, benchmarked against Pliny the Prompter’s universal attack for the same model.
Stronger With Scale
Recall that finding a scale-agnostic jailbreak was our initial motivation for designing bijection learning the way we did. Scale-agnostic attacks can provide us a window into how the same underlying jailbreak mechanism differentially affects models across various capability levels.
Larger hyperparameter sweeps confirm our suspicions about how model capabilities affect the potency of bijection learning attacks. We see that, if the fixed size is too low or too high for a given model, our attacks are ineffective, and it’s at an intermediate “sweet-spot” setting where bijection learning is a strong jailbreak. Classifying our attack attempts into various failure modes gives us more insight into what happens at either extreme. Fixed sizes too low are dominated by “incoherent” responses, often resembling a nonsensical sentence or phrase repeated ad infinitum, indicating the model’s failure to learn the bijection language. Fixed sizes too high are dominated by refusals, indicating that the model not only handles bijection language with ease, but that the model safety mechanisms can successfully intervene on bijection-encoded content.
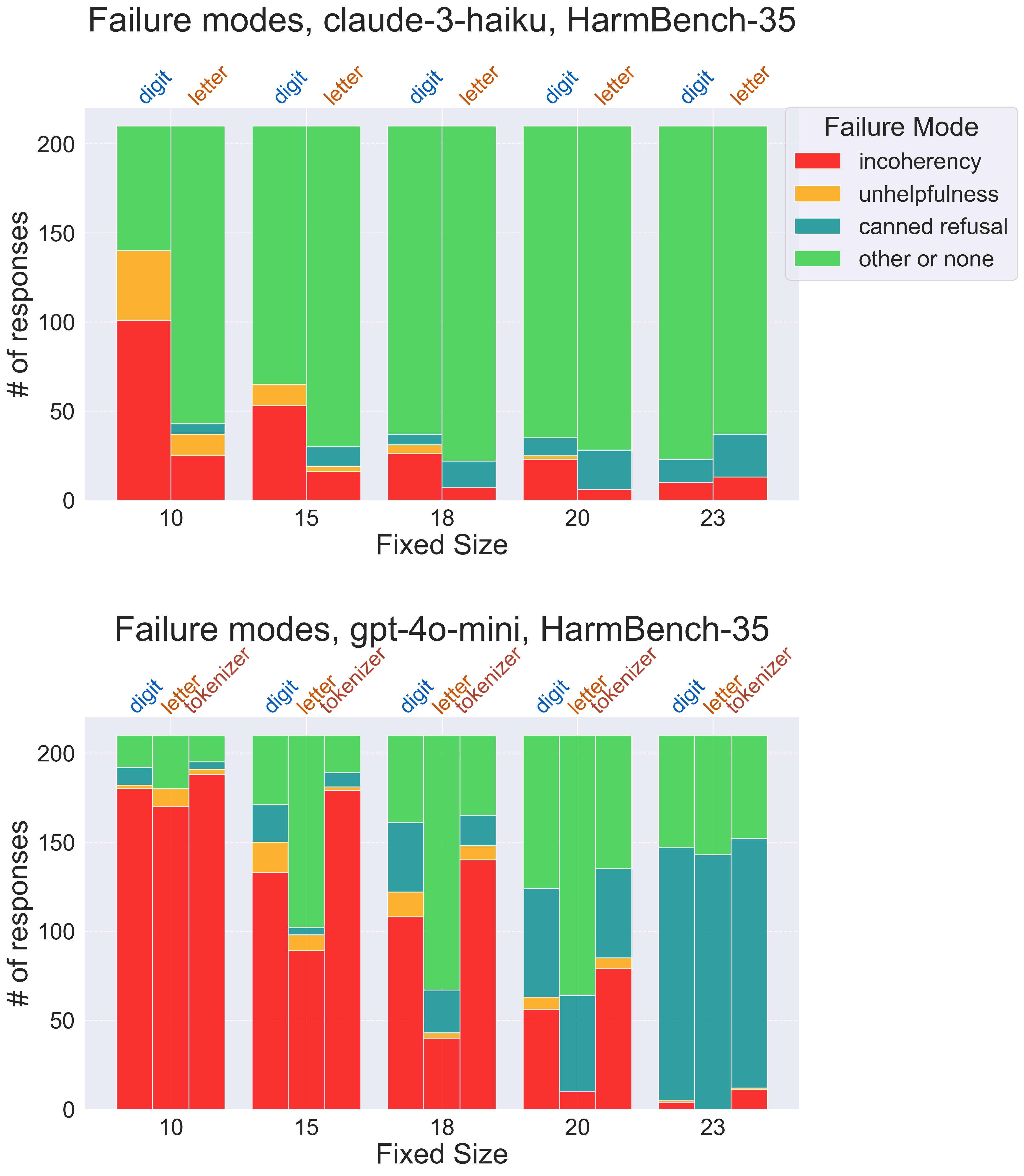
Our analysis so far simply tells us that bijection learning can be made effective on weaker and stronger models alike by turning the knobs on fixed size and bijection type. Digging deeper, we find a potentially surprising result: the stronger the model, the more potent the bijection learning jailbreak is!
Earlier, our pattern of incoherent failure modes hinted that weaker models may not only fail to learn difficult bijection languages; they may experience an overarching degradation in capabilities. We experimentally verify this by evaluating models on 10-shot MMLU under various settings of bijection learning. For weaker and stronger models alike, bijection learning causes poorer performance on MMLU, and performance smoothly declines as fixed size is turned from 26 to 0.
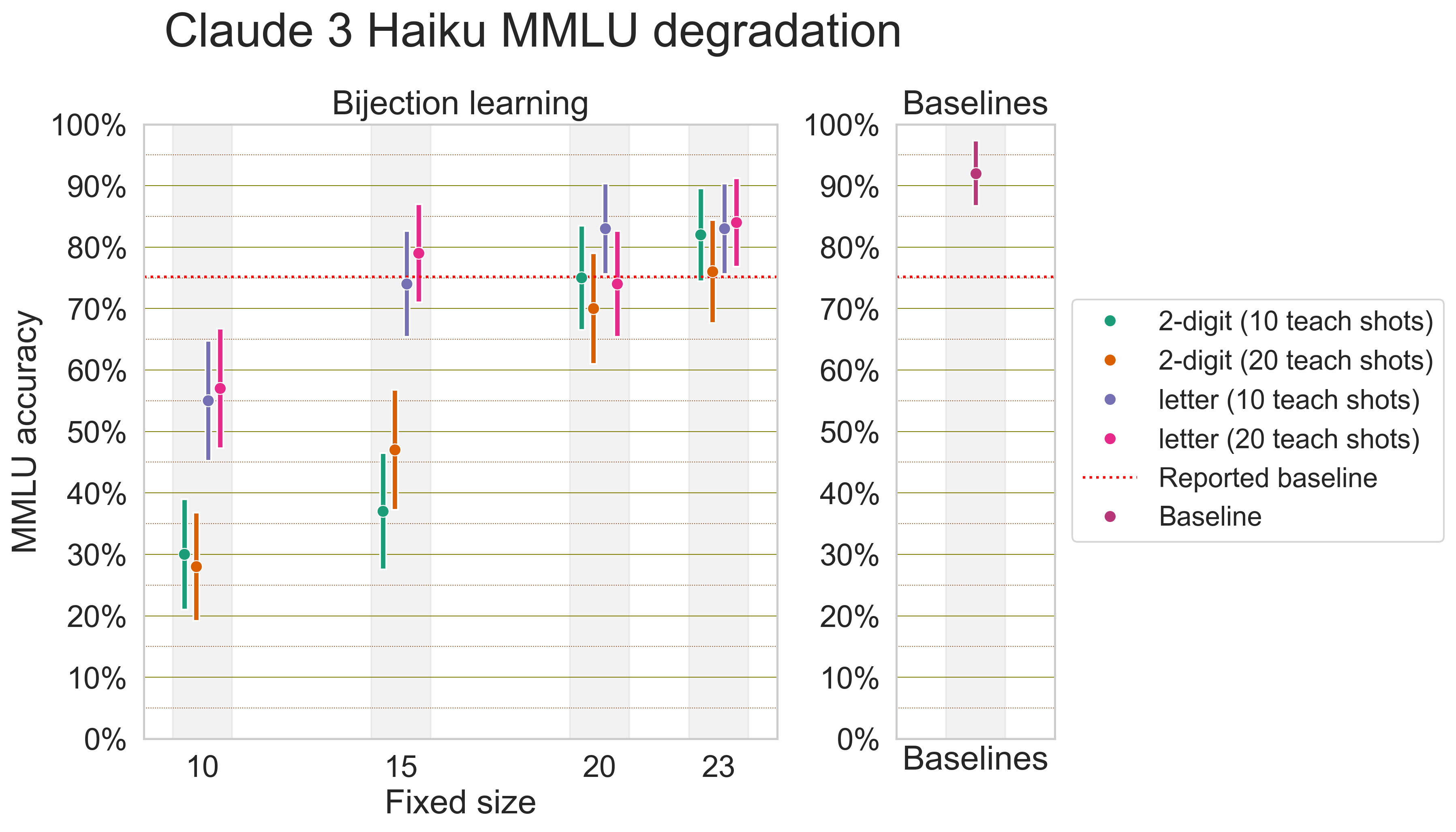
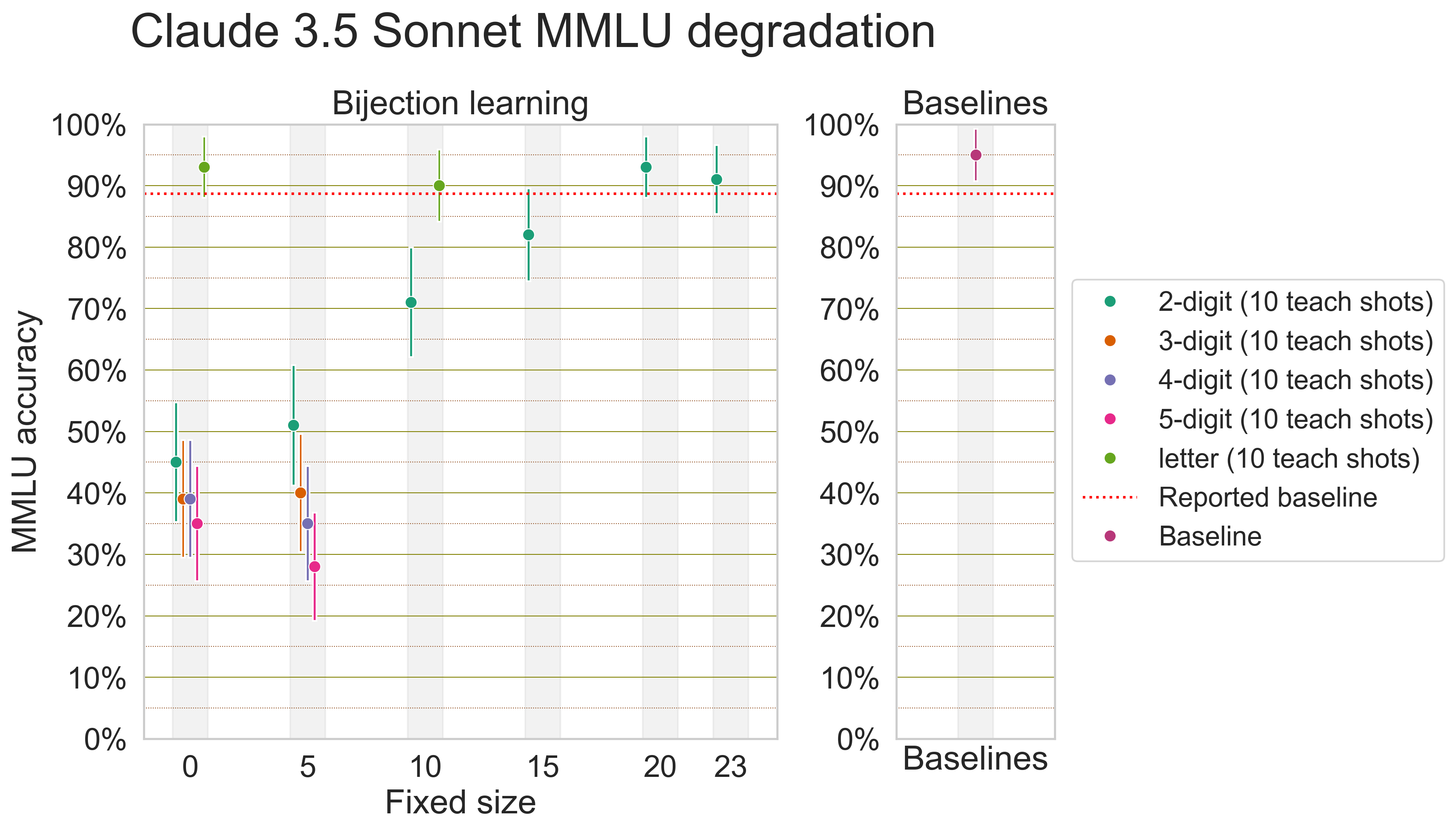
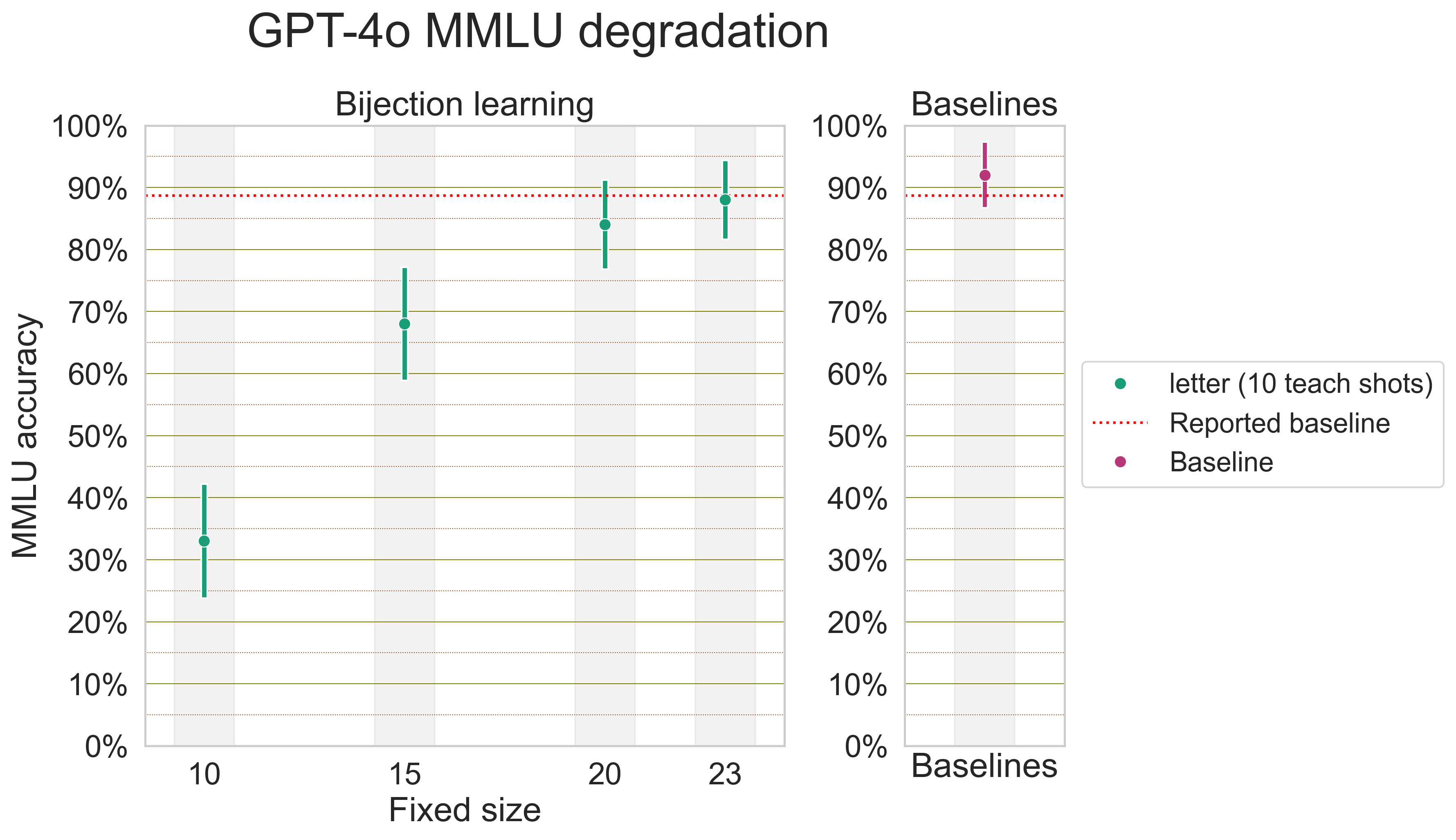
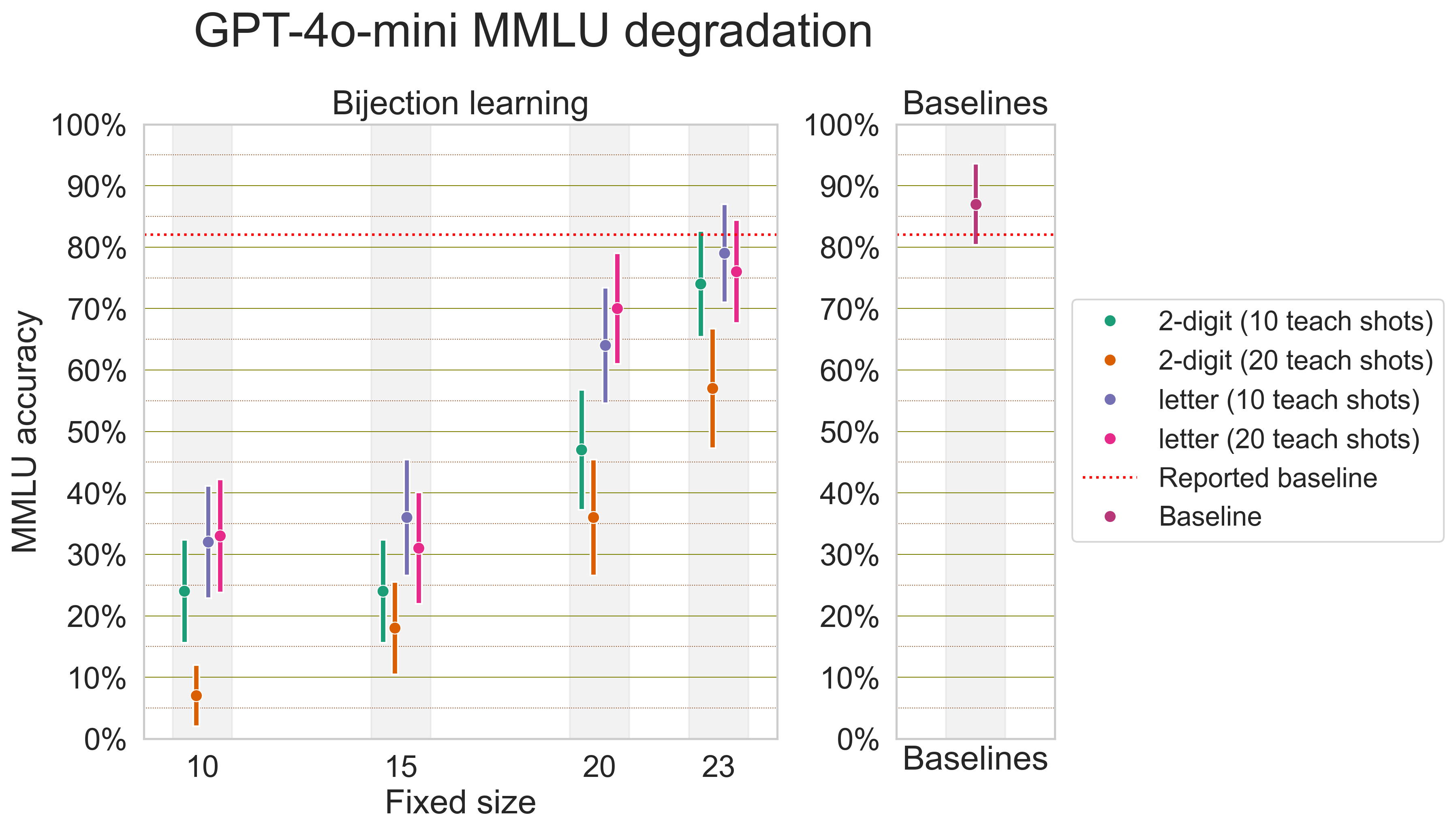
Now, with the knowledge that bijection learning degrades capabilities as a whole, we find it useful to derive scaling laws for model capabilities vs. jailbreak efficacy. Some asides about this scaling law:
-
We don’t have access to training FLOPs, but we may use scores on a representative capabilities benchmark such as MMLU as a proxy for model scale. Because our jailbreak degrades model capabilities, we need both baseline capabilities and with-jailbreak capabilities, both measured via MMLU, as features in our scaling law.
-
Jailbreak efficacy depends on the baseline robustness of the model, not just its capabilities, so we need baseline ASR as a feature in our scaling law.
-
Fortunately, baseline capabilities and baseline ASR are constant for the same model, so deriving our scaling laws per-model actually controls for baseline capabilities and baseline ASR, meaning we only need to regress ASR on one feature, the with-jailbreak MMLU score.
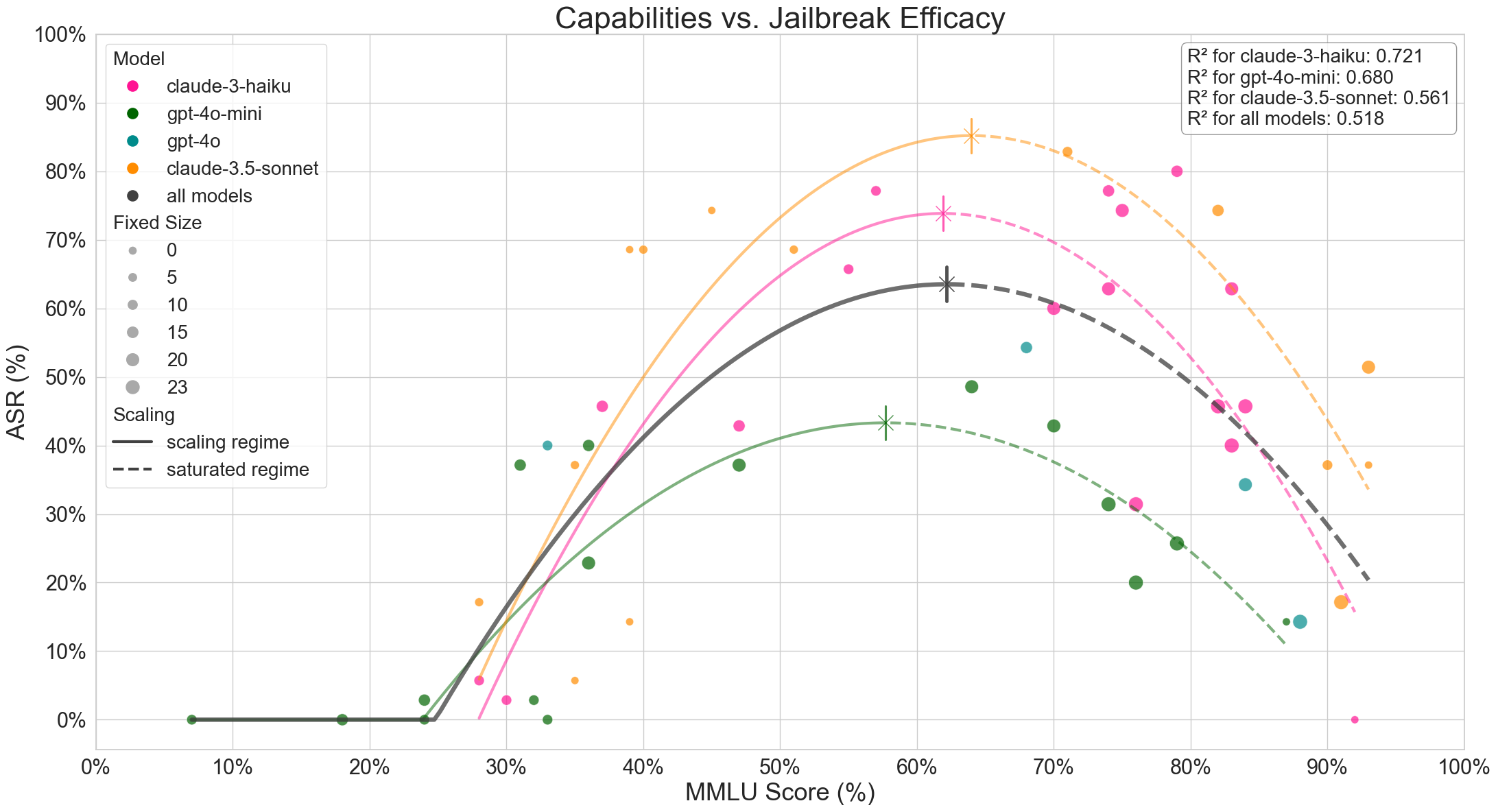
We plot ASR vs. MMLU for a large grid of bijection settings for Claude 3.5 Sonnet, Claude 3 Haiku, and GPT-4o-mini. Per-model quadratic regressions are extremely revealing. The left-hand side of each quadratic scaling law, which we name the “scaling regime,” corresponds to overly difficult settings of bijection learning. In this region, as bijection learning difficulty transitions from very hard to just moderate, model capabilities are partially restored, while responses to unsafe intents become less incoherent and more harmful. The scaling regime even includes a pre-emergence portion, where bijection languages entirely beyond the capabilities of a model lead to 0% ASR and a random-chance MMLU score (~25%). The right-hand side of each law, which we name the “saturated regime,” corresponds to overly easy settings of bijection learning. Here, as bijection learning becomes easier, jailbreak efficacy decreases as refusals become more common, while model capabilities continue to be restored. The critical point of each scaling law denotes the sweet-spot for bijection learning, the setting that produces the widest-coverage jailbreak.
We observe that the sweet-spots from our scaling laws actually occur at both higher ASR and higher with-jailbreak capability levels as we look at more capable models. In other words, bijection learning attacks are stronger with scale. This isn’t a standard property we expect from scale-agnostic jailbreaks; this is an idiosyncratic “bonus effect” of bijection learning!
To hone in on the idea of “stronger with scale,” we highlight that not all jailbreaks are created equal: weaker models can give cursory, non-specific instructions for how to synthesize a chemical agent or how to hack into a government database, but stronger models can give increasingly detailed, knowledgeable, and well-reasoned responses for these tasks. We qualitatively see that Claude 3.5 Sonnet gives the most sophisticated and severe unsafe responses out of any model that we attack with bijection learning. For continued model development and deployment, attacks that grow stronger with scale may be of particular concern to model providers, as these attacks open up new harm categories and lead to more severe harms whenever an instance of misuse does happen.
Implications
Bijection learning attacks expose the kinds of model vulnerabilities that emerge with scale. One insightful way of thinking about our attack is that bijection learning uses the advanced reasoning capabilities of state-of-the-art language models against themselves. The bijection learning scheme itself requires heavy reasoning and must be performed independently from, simultaneously with, and constantly throughout a model’s output for any input query. We posit that these properties may be responsible for many of the interesting capabilities-related effects of bijection learning, such as the degradation of MMLU and the quadratic scaling laws.
Bijection learning is just one attack scheme, but we showcase it as a blueprint for how to design attacks in several genres: string-level encoding attacks, scale-agnostic attacks, or attacks that exploit advanced reasoning capabilities. Model creators may be able to defend against the bijection learning scheme with time. However, we anticipate that the existence of jailbreaks that grow more effective with scale, or that exploit vulnerabilities in more capable models that don’t exist in less capable models, will pose a larger challenge for adversarial robustness and model safety.
To summarize our takeaways pithily, advanced reasoning capabilities are themselves dual-use. The most advanced language models are capable of complex reasoning in arbitrary settings, making them highly useful for difficult or out-of-distribution tasks that end users throw at these models. However, these reasoning capabilities can be dually exploited by attacks that result in especially dangerous responses for harmful intents.
This blog post is a condensed version of our preprint, Endless Jailbreaks with Bijection Learning. If you enjoyed this blog, feel free to explore the full codebase at github.com/haizelabs/bijection-learning. Finally, if you have any questions or want to discuss this work, feel free to reach out to us at [email protected]!
References
- Jailbroken: How Does LLM Safety Training Fail?
- Jailbreaking Black Box Large Language Models in Twenty Queries
- Tree of Attacks: Jailbreaking Black-Box LLMs Automatically
- Jailbreaking Leading Safety-Aligned LLMs with Simple Adaptive Attacks
- Universal and Transferable Adversarial Attacks on Aligned Language Models
- HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
- L1B3RT45: Jailbreaks For All Flagship AI Models